斜坡上的杂化野草,谁说不是一草一千秋,一花一世界呢? –龙应台 《目送》
先来个背景
大数据持续火热,需要处理的数据越来越多,在大数据技术的浪潮中,出现了很多优秀的工具和产品,其中最具影响力的非Hadoop莫属,Hadoop提供了存储和计算方案,基本解决了大数据处理遇到的问题。但是也暴露了一些问题,如基于Hadoop的Map-Reduce计算框架,仅适合批量的离线计算,虽然吞吐率可以满足,但计算效率不能满足即席查询Ad-Hoc的性能要求,有了市场痛点,相应的解决痛点的产品就会应声而出,所以Presto就在Facebook诞生了。
如何描述这货呢
Presto是一个开源的分布式SQL查询引擎,用于对 GB 到 PB 量级的数据源,进行交互式查询。
这货能干啥
Presto可以查询多种平台上的数据,包括Hive、Cassandra、关系数据库甚至专有数据存储,并且可以将多个数据源的数据进行组合查询。Presto的目标客户是那些预期查询响应时间从亚秒到分钟不等的分析师。之前的数据分析工具分为两种:一种是使用昂贵的商业解决方案进行快速分析,另外一种是需要过多硬件的缓慢的“免费”解决方案。Presto提供的方案不用以上两种,但同时具备了他们的优点:分析速度快、免费。
特点列举
| 特点 | 说明 |
|---|---|
| 多数据源 | 可以支持MySQL、PG、Cassandra、Hive、Kafka、JMX等多种数据源 |
| 扩展性 | 设计非常牛X, 扩展性非常强悍,目测是Apache产品扩展性前三的产品 |
| 支持SQL查询 | 完全支持ANSI SQL, 并带有Presto特有的SQL扩展项 |
| 流水线 | 基于Pipeline模式设计,在海量数据处理过程中,终端用户不用等待所有的数据都处理完毕后才能看到结果,一旦计算开始,结果数据就会一部分一部分的产出,并被终端用户看到 |
| 混合计算 | 针对一种类型的Connector可以配置一个或者多个Catalog,终端用户可以混合多个Catalog进行相关的计算,例如stats和hive的表进行join |
| 高性能 | 查询性能是Hive MR的10倍以上 |
基本概念
服务进程
Presto中有两种类型的服务进程: Coordinators服务进程和Workers服务进程;
Coordinators服务进程
Coordinators服务进程部署于集群中一个独立的节点上,是Presto集群的管理节点。主要的作用包括接受查询请求、解析查询语句、生成查询执行计划、任务调度和Worker进程管理。不仅与Worker进程进行通信从而获得Worker的状态信息,还需要与Client进行通信,接受查询请求等。
Worker服务进程
Worker进程主要是执行查询任务,直白说就是真正干活的。一个Presto集群中,存在一个Coordinators节点个多个Worker节点,Coordinators节点是管理节点,Worker节点是工作节点。在每个Worker节点上都会存在至少一个Worker服务进程,该服务进程主要进行数据处理及任务Task的执行。
连接器(Connector)
Presto是通过各种连接器(Connector)来访问不同的数据源的,可以将连接器(Connector)当作Presto访问各种数据源的驱动程序。连接器(Connector)是Presto的SPI的实现,允许Presto使用标准API与资源进行交互。 Presto包含多个内置连接器(Connector),并且允许第三方开发自定义连接器(Connector),以便Presto能够访问各种数据源中的数据。
目录(Catalog)
Presto中的目录(Catalog)类似于MySQL中的一个数据库实例,每个目录(Catalog)都与特定的连接器(Connector)相关联。可以让多个目录(Catalog)使用同一个连接器(Connector)访问相同数据库的两个不同实例。例如,如果您有两个Hive集群,您可以在一个Presto集群中配置两个目录(Catalog),它们都使用Hive连接器(Connector),允许您从两个Hive集群(甚至在同一个SQL查询中)查询数据。
模式(Schema)
模式(Schema)是组织表的一种方式。类似MySQL中的Database。目录(Catalog)和模式(Schema)一起定义了一组可以查询的表。当使用Presto访问Hive或PG等关系数据库时,模式(Schema)在目标数据库中转换为Database的概念。其他类型的连接器(Connector)可以选择对底层数据源有意义的方式将表组织到模式(Schema)中。
表(Table)
表(Table)是一组无序的行,它们被组织成具有类型的命名列。与传统数据库中的Table含义是一样的,从数据源到表(Table)的映射是由连接器(Connector)定义的。
查询执行模型
Presto在执行SQL语句时,会将这些语句转换为可在分布式Coordinators和Worker节点上执行的查询。
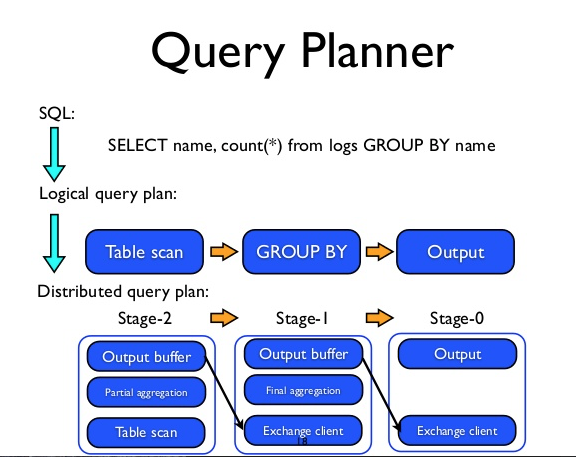
语句(Statement)
其实就是我们输入的SQL语句,这种语句由子句(Clause)、表达式(Expression)、断言(Predicate)组成.
查询执行(Query)
当Presto接受一个SQL语句(Statement)后,会解析该SQL语句(Statement),将其转换成一个查询执行(Query)和相关的查询执行计划。一个查询执行表示可以在Presto集群上运行的查询,是由运行在各个Worker上且各自之间相互关联的阶段(Stage)组成的。这表名在Presto中,语句(Statement)和查询(Query)是两个不同的概念。两者的区别在于:语句(Statement)是用文字表示的SQL执行语句,而查询执行(Query)是由阶段(Stage)、任务(Task)、驱动器(Driver)、分片(Split)、操作符(Operator)和数据源(Data Source)组成,这些组件通过内部联系共同组成了一个查询执行,从而得到SQL语句表述的查询。
阶段(Stage)
1
| |
Stage表示查询执行阶段。当Presto运行查询执行(Query)时,Presto会将一个查询执行(Query)拆分成具有层次关系的多个阶段(Stage),一个阶段(Stage)代表查询执行计划的一部分。例如,我们执行一个查询,从Hive的某张表中查询数据并进行一些聚合操作,Presto会创建一个Root Stage, 该Stage聚合其上游Stage的输出数据,然后将结果输出给Coordinator, 并由Coordinator将结果输出给终端用户。 阶段(Stage)是有层级关系的,每个查询执行(Query)都会有一个Root Stage, 该阶段(Stage)用于聚集上游阶段(Stage)的输出数据,并将最终结果反馈给用户。再次强调,阶段(Stage)只是Coordinator用于对查询执行计划进行管理和建模的逻辑概念。阶段(Stage)根据作用可分为以下四类:
| Stage类型 | 作用 |
|---|---|
| Coordinator_Only Stage | 表结构的变更(创建或者更改) |
| Single or Root Stage | 聚合上游Stage的输出数据,并将最终数据输出给终端用户 |
| Fixed Stage | 接收子Stage产出的数据并在集群中对这些数据进行分布式的聚合或者分组计算 |
| Source Stage | 链接数据源的Stage, 负责从数据源读取数据,同时会对查询执行计划的优化结果完成相应的操作,如断言下发、条件过滤等。 |
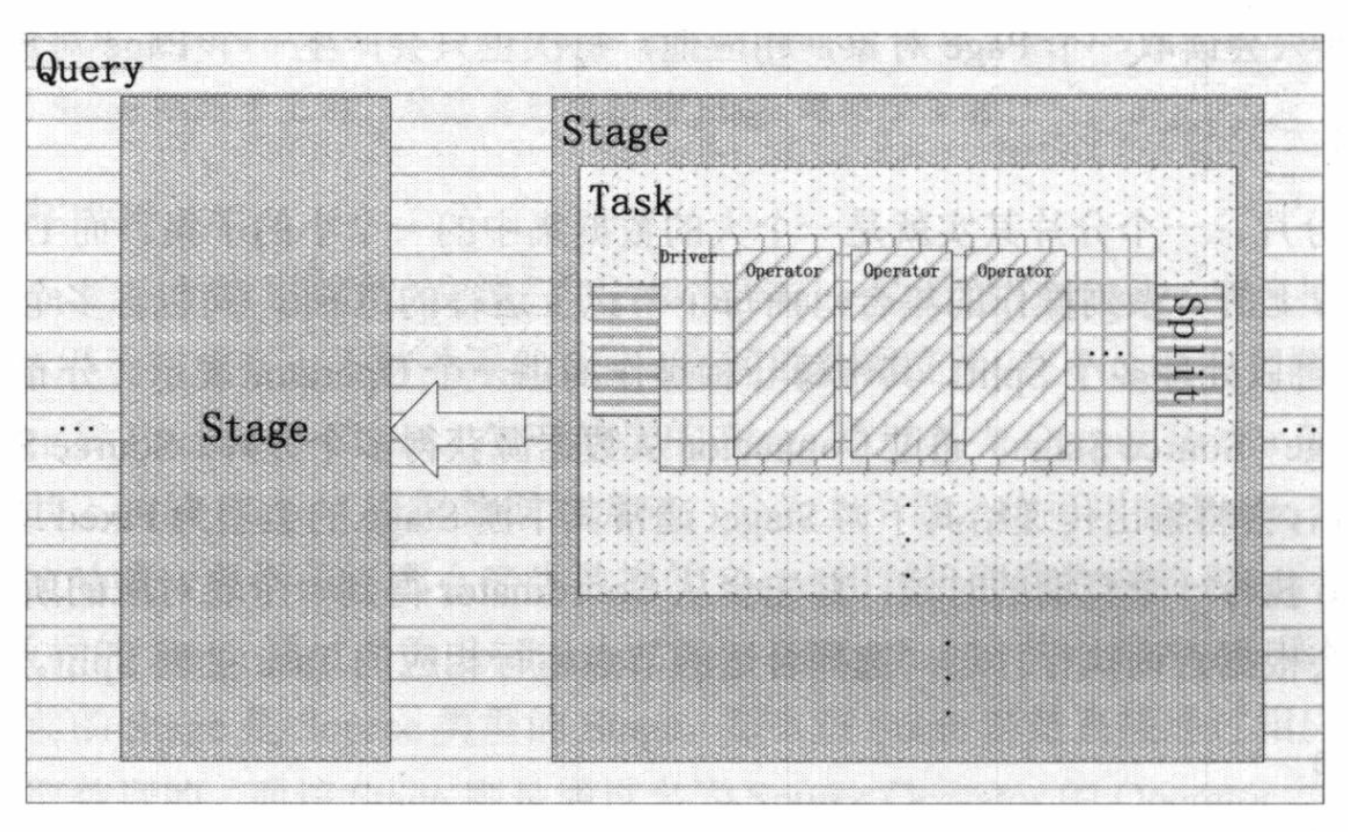
任务(Task)
上面讲到的Stage并不会在Presto集群中实际运行,他仅仅代表针对于一个SQL语句查询执行(Query)中的一部分查询的执行过程,只是用来对查询执行(Query)计划进行管理和建模。Stage在逻辑上被分为一系列的任务(Task), 而这些任务(Task)则是需要实际运行在Presto的各个Worker节点上的。Presto的层次设计非常清晰,一个查询执行(Query)被分解成具有层析关系的多个阶段(Stage),一个阶段(Stage)又被拆分成一系列的任务(Task),每个任务(Task)处理一个或者读个分片(Split);每个阶段(Stage)被分解成多个任务(Task), 从而可以并行的执行一个阶段(Stage);任务(Task)也采用了相同的机制,一个Task也被分成了多个驱动器(Driver),从而可以并行的执行一个任务(Task);
驱动器(Driver)
任务(Task)包含一个或多个并行驱动器(Driver)。驱动器(Driver)对数据进行操作,并结合操作符(Operator)生成输出,然后由一个任务(Task)聚合输出,然后在另一个阶段(Stage)交付给另一个任务(Task)。驱动器(Driver)是操作符(Operator)实例的序列,或者您可以将驱动器(Driver)看作内存中的操作符(Operator)的物理集合。它是Presto架构中最低的并行级别。
分片(Split)
一个分片(Split)其实就是一个大的数据集中的一个小的子集,分布式查询计划的最低级别阶段通过连接器的片段检索数据,而分布式查询计划(Query)的较高级别阶段从其他阶段(Stage)检索数据。当Presto调度查询时,协调器(Coordinator)将查询连接器(Connector),以获得表可用的所有分片(Split)的列表。协调器(Coordinator)跟踪哪些机器正在运行哪些任务(Task),以及哪些分片(Split)由哪些任务(Task)处理。
操作符(Operator)
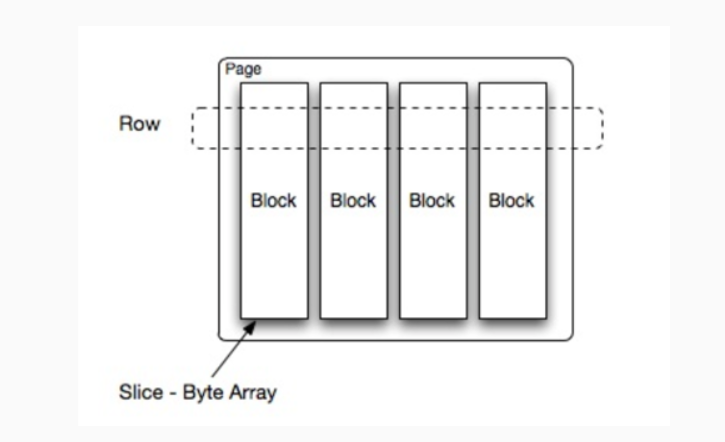
一个操作符(Operator)代表对一个分片(Split)的一种操作,例如过滤、转换等。一个操作符(Operator)依次读取一个分片(Split)中的数据,将操作符(Operator)所代表的计算和操作用于分片(Split)的数据上,并产生输出。每个操作符(Operator)均会以页(Page)为最小处理单位分别读取输入数据和产出输出数据。操作符(Operator)每次一会读取一个页(Page)对象,同理也只会产生一个页(Page)对象。 page## 页(Page) 页(Page)是Presto中处理的最小数据单元,一个页(Page)对象包含多个数据Block; 可以将数据Block理解成一个字节数组,存储一个字段的若干行;多个Block横切的一行其实就是一行真实的数据。下图展示了Page和Block的关系
交换(Exchange)
交换(Exchange)用于查询的不同阶段(Stage)的Presto节点之间的数据传输。任务(Task)将数据生成到输出缓冲区中,下游阶段(Stage)通过名为Exchange Client的Exchange从上游阶段(Stage)读取数据。 交换(Exchange)其实就是用于完成具有上下游关系的阶段(Stage)之间的数据交换。
模型关系
整体架构
下面两张图(有色和无色)比较直观的表示出Presto的整体架构,主从结构在大数据项目上真是无所不在。
无色结构图
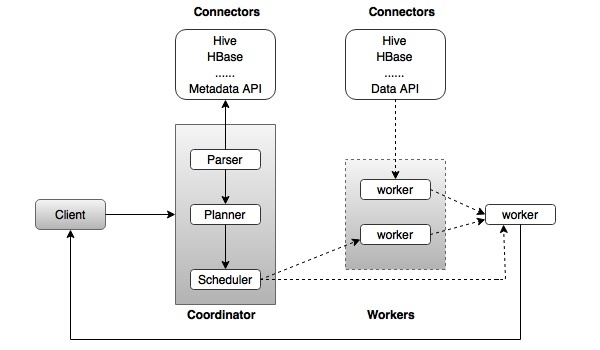
无色结构图
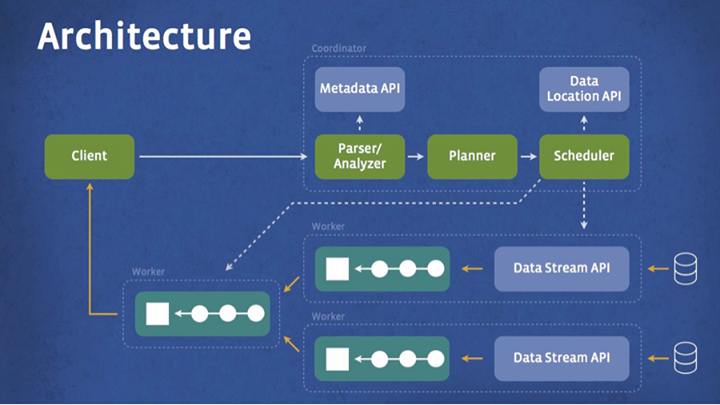
查询执行步骤
- 客户端将SQL发送给Presto集群的Coordinator
- Coordinator收到查询语句后,对语句进行解析,生成查询执行计划,并且会根据数据本地性生成对应的HttpRemoteTask
- Coordinator将每个Task发送到对应的Worker上,策略就是数据本地性
- 执行处于上游Source Stage中的Task,主要是从Connector读取数据
- 处于下游Stage的Task读取上游Stage产出的数据结果,并在该Stage每个Task所在的Worker的内存中进行后续的计算和处理
- Coordinator将Task分发后,就会连续不断的从Root Stage中的Task获取计算结果,并缓存起来,直到所有计算结束
- Client提交查询后,会不停的从Coordinator获取查询结果,获取一部分展示一部分,结果全部获取完表示查询结束
应用场景
- Ad-Hoc(常用)
- ETL(INSERT INTO TABLE AS SELECT )
- Pseudo Real Time Computation(Kakfa-Connector)
总结
从背景、功能、特点、概念、架构、使用场景等角度描述了Presto,算是入门篇吧~~~