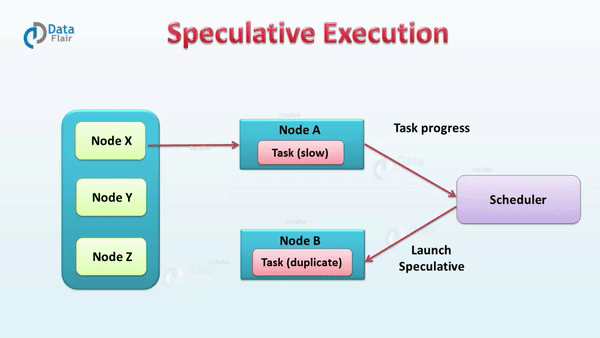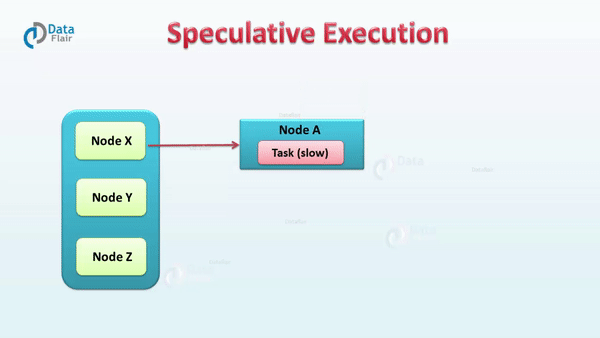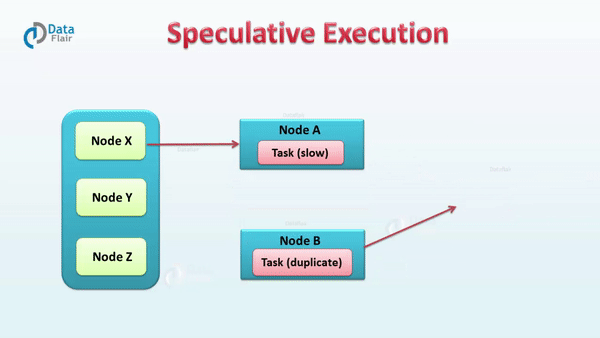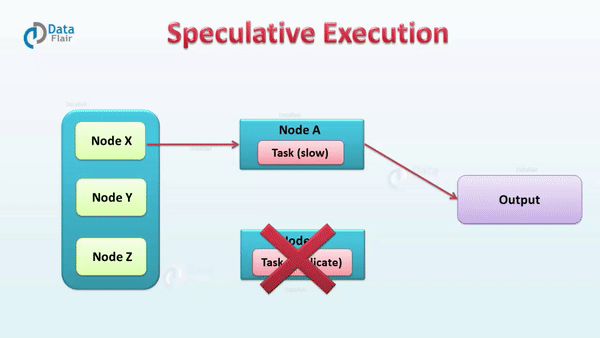
// 类名:org.apache.spark.scheduler.TaskSchedulerImploverridedefstart(){backend.start()// 非本地调度后端且推测执行参数设置为trueif(!isLocal&&conf.getBoolean("spark.speculation",false)){logInfo("Starting speculative execution thread")// 启动推测执行线程speculationScheduler.scheduleWithFixedDelay(newRunnable{overridedefrun():Unit=Utils.tryOrStopSparkContext(sc){// 检查所有的处于活跃状态的任务checkSpeculatableTasks()}// SPECULATION_INTERVAL_MS 是 spark.speculation.interval的值},SPECULATION_INTERVAL_MS,SPECULATION_INTERVAL_MS,TimeUnit.MILLISECONDS)}}// How often to check for speculative tasksvalSPECULATION_INTERVAL_MS=conf.getTimeAsMs("spark.speculation.interval","100ms")
// 类名:org.apache.spark.scheduler.TaskSchedulerImpl// 检查所有的处于活跃状态的任务defcheckSpeculatableTasks(){varshouldRevive=falsesynchronized{// 判断是否有需要推测执行的任务shouldRevive=rootPool.checkSpeculatableTasks(MIN_TIME_TO_SPECULATION)}if(shouldRevive){backend.reviveOffers()}}// 类名:org.apache.spark.scheduler.TaskSetManageroverridedefcheckSpeculatableTasks(minTimeToSpeculation:Int):Boolean={// Can't speculate if we only have one task, and no need to speculate if the task set is a// zombie.if(isZombie||numTasks==1){returnfalse}varfoundTasks=false// 计算启动推测执行需要完成任务数的最小值valminFinishedForSpeculation=(SPECULATION_QUANTILE*numTasks).floor.toIntlogDebug("Checking for speculative tasks: minFinished = "+minFinishedForSpeculation)// 如果成功的任务数大于上面计算的阈值并且成功的任务数大于0,进入推测执行检查if(tasksSuccessful>=minFinishedForSpeculation&&tasksSuccessful>0){valtime=clock.getTimeMillis()// 成功执行Task的执行成功时间的中位数valmedianDuration=successfulTaskDurations.median// 取中位数的SPECULATION_MULTIPLIER倍和minTimeToSpeculation的最大值作为阈值thresholdvalthreshold=max(SPECULATION_MULTIPLIER*medianDuration,minTimeToSpeculation)// TODO: Threshold should also look at standard deviation of task durations and have a lower// bound based on that.logDebug("Task length threshold for speculation: "+threshold)// 遍历所有需要判断推测执行的taskfor(tid<-runningTasksSet){valinfo=taskInfos(tid)valindex=info.index// 放入推测执行任务列表的条件:任务为成功、任务正在执行、任务执行时间超过threshold且未在推测执行任务列表if(!successful(index)&&copiesRunning(index)==1&&info.timeRunning(time)>threshold&&!speculatableTasks.contains(index)){logInfo("Marking task %d in stage %s (on %s) as speculatable because it ran more than %.0f ms".format(index,taskSet.id,info.host,threshold))speculatableTasks+=indexsched.dagScheduler.speculativeTaskSubmitted(tasks(index))foundTasks=true}}}foundTasks}// Quantile of tasks at which to start speculationvalSPECULATION_QUANTILE=conf.getDouble("spark.speculation.quantile",0.75)valSPECULATION_MULTIPLIER=conf.getDouble("spark.speculation.multiplier",1.5)