人生就是如此,你以为已经从一个漩涡逃离,其实另外一个漩涡就在你的脚下。用力蹬一脚,就进去了。所以,不需要对生活太用力,心会带着我们去该去的地方。 –龙应台
原文地址:https://www.da-platform.com/blog/differences-between-savepoints-and-checkpoints-in-flink
保存点和检查点分别是什么?
Apache Flink保存点是一种允许对整个流应用程序进行“时间点”快照的特性。此快照包含关于您在输入中的位置的信息,以及关于源的所有位置和整个应用程序状态的信息。我们可以在不停止应用程序的情况下通过使用Chandy-Lamport算法的变体获得整个状态的一致快照。保存点包含两个主要元素:
- 首先,保存点包括一个目录,目录中包含(通常较大的)二进制文件,这些文件表示流应用程序在检查点/保存点处的整个状态
- 一个(相对较小的)元数据文件,它包含指向保存点的所有文件的指针(路径),这些文件存储在所选的分布式文件系统或数据存储中。
请阅读我们之前的博客文章,了解如何在流应用程序中启用保存点的详细步骤。
上面关于保存点的所有内容听起来与我们在前面的一篇文章中解释的Apache Flink中的检查点非常相似。检查点是Apache Flink用于从故障中恢复的内部机制,包括应用程序状态的副本和输入的读取位置。在失败的情况下,Flink通过从检查点加载应用程序状态并继续从恢复的读取位置恢复应用程序,就像什么都没有发生一样。
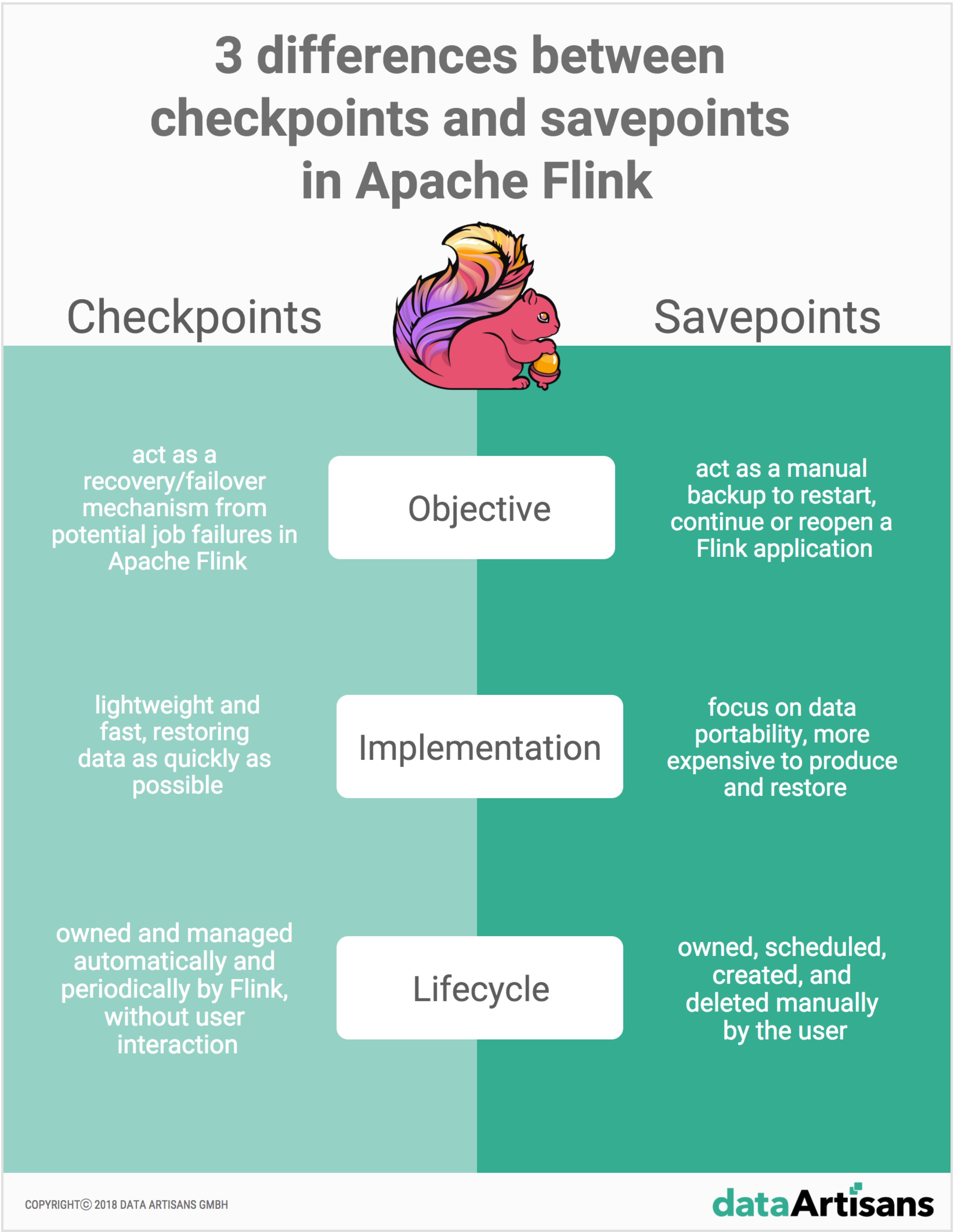
Apache Flink中保存点和检查点之间的3个差异
检查点和保存点是Apache Flink作为流处理框架非常独特的两个特性。保存点和检查点在它们的实现中可能看起来很相似,但是,这两个特性在以下3个方面有所不同:
- 目的:从概念上讲,Flink的保存点不同于检查点,就像备份不同于传统数据库系统中的恢复日志一样。检查点的主要目标是充当Apache Flink中的恢复机制,确保一个容错处理框架能够从潜在的作业失败中恢复。相反,Savepoints的主要目标是作为在用户手动备份和恢复活动之后重新启动、继续或重新打开暂停的应用程序的方式。
- 实现:检查点和保存点的实现是不同的。检查点被设计成轻量级和快速的。例如,使用RocksDB状态后端的增量检查点使用RocksDB的内部格式,而不是Flink的本机格式。这用于加快RocksDB的检查点进程,使其成为更轻量级检查点机制的第一个实例。相反,保存点的设计目的是更加关注数据的可移植性,并支持对作业所做的任何更改,这些更改会使生成和恢复保存点的成本稍微高一些。
- 生命周期:检查点本质上是自动的、周期性的。它们由Flink自动地、定期地创建和删除,不需要任何用户交互,以确保在意外的作业失败时能够完全恢复。相反,保存点是由用户手动拥有和管理的(即它们是计划、创建和删除的)。
什么时候在流应用程序中使用保存点?
尽管流处理应用程序处理连续生成的数据(数据“在动”),但是在某些情况下,应用程序可能需要重新处理以前处理过的数据。Apache Flink中的保存点允许您在以下情况下这样做:
- 部署流应用程序的更新版本,包括新特性、bug修复或更好的机器学习模型。
- 为应用程序引入A/B测试,使用相同的源数据流测试程序的不同版本,在不牺牲先前状态的情况下从相同的时间点开始测试。
- 在需要更多资源的情况下重新调整应用程序。
- 将流应用程序迁移到新的Apache Flink版本,或者将应用程序升级到不同的集群。
结论
Apache Flink检查站和保存点是两个不同的特性,适用于不同的需求,以确保一致性、容错和确保应用程序状态保存在意想不到的工作失败(检查点)以及在升级的情况下,bug修复、迁移或A / B测试(使用保存点)。这两个特性结合在一起,可以在不同的实例中确保应用程序的状态在不同的场景和环境中保持不变。